The discussion about language quality and its downfall is not recent and has been ever present since humans first started to talk. Just like Molière's writing was not considered, at his time, to be of the same quality as his peers, he is now considered the standard of the french language, showing how standards evolve over time. However, it is interesting to note that while social media platforms have always been the target of mockery when talking about language quality, we do see sentiments of users criticising its downfall within the platform itself. Are these concerns verifiable, or can high-quality language still be found within Reddit?
- How to quantify linguistic quality? Which metrics can reliably be used?
- To what extent linguistic quality varies between Reddit users?
- How does linguistic quality vary across broad subreddit communities? Which stand out in terms of higher or lower quality and why?
- How does linguistic quality relate to sentiment and tone across Reddit? In particular, is there a link between negative sentiment, insults and hostility and language quality?
1. Dataset
Hyperlinks
Our primary dataset consists of the "Subreddit Hyperlinks Network." This is a massive collection of posts where one subreddit links to another. While it does not provides us with the raw text body of the posts, it does provide timestamps, sentiment labels and 86 different linguistic metrics (from low-level metrics such as the number of characters in the post, to high-end metrics derived from LIWC, a state-of-the-art linguistics model), allowing us to analyze in-depth the way users express themselves.
Embeddings
Along with the initial subreddit hyperlinks dataset, we used another dataset: the embedding vectors of subreddits.
These embeddings are high-dimensional vectors (in our case, 300 dimensions). They are designed to represent similarities between data points in a complex space. Specifically, each of the ~50,000 subreddits is assigned a 300-dimensional vector. These vectors indicate similarity based on user behavior: if many users post in the same group of subreddits, those subreddits will be closer to each other in this 300-dimensional space.
These embeddings are very useful for our research on linguistic quality and our goal to determine "who speaks the best". They allow us to identify clusters of subreddits where users share similar interests, effectively grouping subreddits into distinct communities.
Weakness
While these embeddings are powerful and perform well, the dataset faces challenges due to the nature of Reddit communities and the high number of data.
Indeed communities are not perfectly separated into 'clean' clusters where we can easily say: 'These users are only interested in politics.' Most users have diverse interests and post in a wide variety of subreddits. This creates a significant amount of overlap between vectors. Consequently, some subreddits appear very close to many others in the 300-dimensional space, which can create 'noisy' links and blur the boundaries between different communities.
Visualizing the Embedding Weaknesses
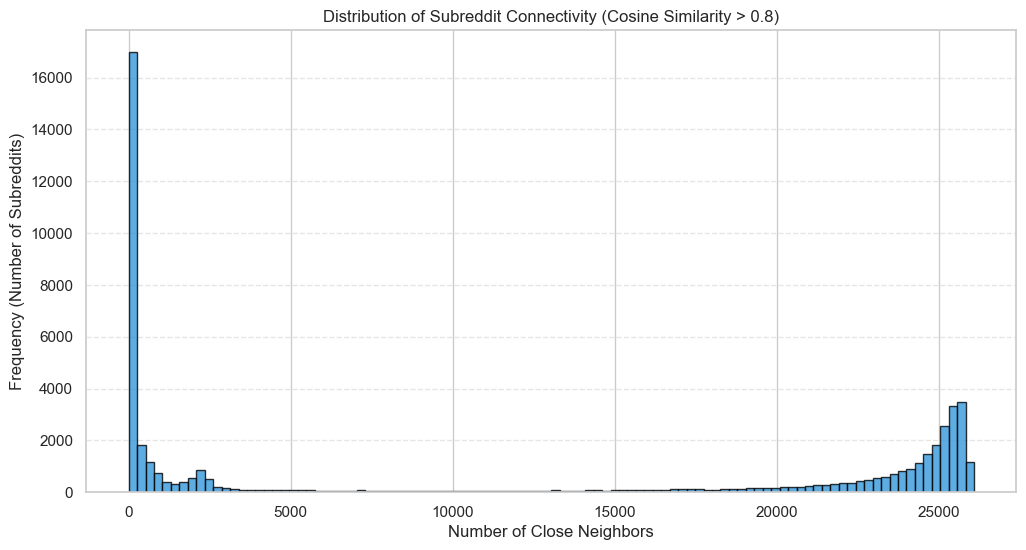
The following graphs illustrate the "fuzzy" nature of these communities. On Figure 1, a 2D projection (using dimensionality reduction) of the 50,000 subreddits shows the 300-dimensional vectors in a 2D-space. Each point represents a subreddit (put your mouse on a point to see which one). We see that the subreddits are not clustered into distinct groups, but rather forming a large, dense circle with significant overlap. We can still identify isolated clusters like on (5, -5) which is quite defined. By zooming and looking at subreddits names, we can see that it should be related to pop culture or video-games with subreddits like capecodegaming, interactivecinema or virtualrealitygaming. Nevertheless it is hard to confirm this since there is a lot of noise. There is also subreddits as snowskating or abstraction. This visualization confirms that many communities are not clearly separated.
On Figure 2, the graph displays the distribution of close neighbors. The x-axis represents the number of neighbors as the y-axis shows the number of subreddits. A close neighbor is defined using cosine similarity. Cosine similarity measures the orientation of two vectors in the 300-dimensional space, ranging from -1 (opposite) to 1 (identical). In order to be closed, a neighbor needs 80% similarity. The distribution reveals a non-negligible number of subreddits that have more than 10,000 neighbors with over 80% similarity.
2. What Is Language Quality?
To calculate the Linguistic Quality Index (LQI), we aggregated four robust dimensions. Click below to see the exact formulas derived from our data processing.
Standard Type-Token Ratio is biased against long texts (the longer you write, the more you repeat common words). We used Herdan's C (Log-TTR) to ensure fair comparison between short comments and long rants.
Simple sentence length is noisy (a 50-word list of groceries is not "complex"). We created a composite score that rewards using longer, more complex words within structurally longer sentences.
Based on Heylighen & Dewaele (2002). This distinguishes "Contextual" language (casual, chatty, subjective: "I think...") from "Formal" language (objective, noun-heavy: "The data suggests...").
Quantifies intellectual nuance. It rewards "Distinction Markers" (e.g., but, however) and "Tentative Language" (e.g., perhaps, likely) while penalizing "Certainty Markers" (e.g., always, never).
$$LQI_{raw} = 4 \cdot C_D + 3 \cdot F_I + 2 \cdot S_C + 1 \cdot L_R$$
Why this weighting? By up-weighting Cognitive Depth (4) and Formality (3), we define quality as dispassionate analysis. This prevents emotional "rants"—which may be structurally complex but highly subjective—from scoring highly, instead rewarding content that is nuanced, objective, and precise.
The final score is quantile-clipped (5th-95th percentile) and MinMax scaled to \([0, 1]\).Feature Analysis
The histograms above show distinct characteristics. For example, lexical_richness shows a sharp spike at 1.0. This artifact represents very short posts (e.g., "Yes", "lol") where every word is unique. This confirms why simple ratios fail and why we need robust metrics. Meanwhile, cognitive_depth often spikes at zero, indicating that a significant portion of Reddit communication is purely phatic or descriptive, lacking explicit reasoning words.
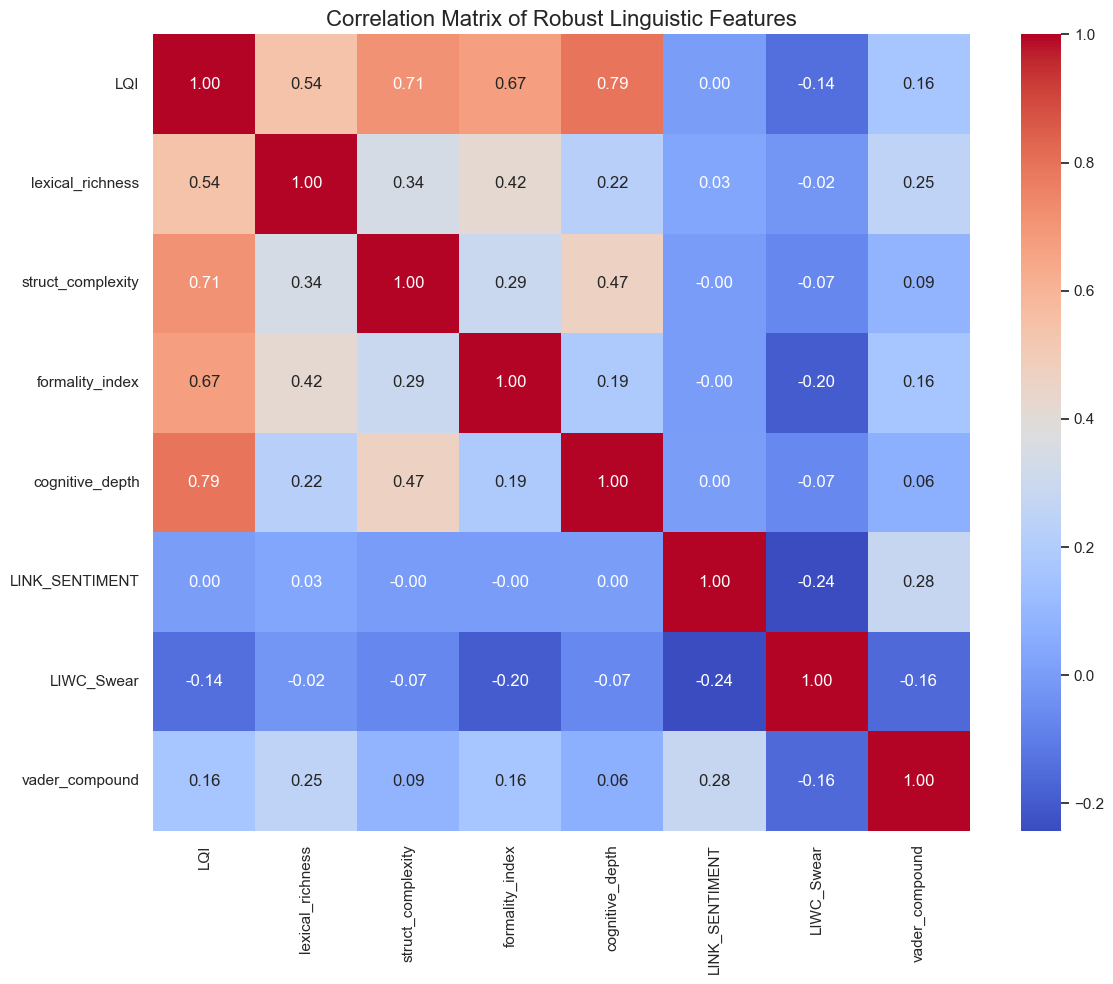 Figure 4: Correlation Matrix of Linguistic Features
Figure 4: Correlation Matrix of Linguistic Features
Orthogonality of Features
An essential check was to ensure our metrics weren't just measuring the same thing four times. As the correlation matrix shows, our chosen features have low overlap.
Interestingly, Structural Complexity and Cognitive Depth have the highest amount of correlation between our four metrics. While it is low enough to understand that they measure different dimensions of the "linguisic profile", it can be explained from the fact that posts with a complex argument will tend to make use of more complex words and sentence structures.
Moreover, the correlation between LQI and different sentiment metrics (such as Link_Sentiment, LIWC_Swear and vader_compound) is quite low. This will be subject to an in-depth analysis in section 6, but it already hints to a low influence of sentimentality on linguistic quality.
3. Linguistic Quality Within Specific Subreddits
Let's try to validate our instincts by checking up on the "best" and "worst" performing subreddits.
Analysis of the Leaderboard:
The distinction is stark. The top-performing subreddits are dominated by specific, knowledge-heavy communities like r/AskHistorians or r/explainlikeimfive. These communities enforce strict moderation policies that require detailed, cited responses, naturally inflating their Structural Complexity and Cognitive Depth scores.
Conversely, the bottom-performing subreddits are populated by meme subreddits and rapid-fire gaming communities. However, "low quality" here doesn't necessarily mean "stupid." It often reflects a different function of language: efficient, high-context communication (memes, slang) that prioritizes speed and communities dependent text structures over formalities.
4. Linguistic variation within a topic/community
Methodology
Clustering Strategy and Challenges
The primary challenge in this analysis stems from "bridges": subreddits frequented by users from vastly different backgrounds. These bridges exhibit a high number of neighbors, making them notoriously difficult to classify. In standard clustering, these points either force the creation of massive, noisy clusters (K-means) or are discarded entirely as outliers (HDBSCAN).
- Why K-means Failed: Our initial attempt using K-means proved inadequate. K-means inherently assumes spherical (circular) cluster shapes and requires a-priori knowledge of the exact number of clusters. Given the nature of Reddit, communities are not perfectly circular; they overlap extensively due to the diverse interests of users. Forcing these high-dimensional "clouds" into rigid spheres resulted in a poor representation of the social reality.
- The Density Limitation of HDBSCAN: was a logical next step due to its ability to handle non-spherical shapes. However, it proved too selective for our dataset. While it identified high-density cores, the resulting clusters were too small, and a significant portion of the subreddits were labeled as outliers.
Refined Clustering Approach
At this stage, we realized our fundamental assumption was flawed: we were looking for predefined topics (e.g., "politics", "video games"). In reality, embeddings capture community behaviors. A cluster might not represent a single subject, but rather a specific demographic of users who share multiple interests.
To refine the methodology, three key improvements were implemented:
- Scope Restriction: Clustering performed exclusively on subreddits in our dataset.
- Recursive Refinement: Clusters were manually reviewed, and noisy groups were re-processed to achieve finer granularity.
- Representative Sampling: Only the 250 subreddits closest to each cluster's centroid were retained.
The first improvement significantly enhanced overall results while reducing the computational load (RAM usage). By filtering out unnecessary data, the number of active subreddits was reduced from ~50,000 to approximately 17,000.
The second improvement expanded the diversity of identified groups. By performing a second clustering pass on the previously discarded "noise," we successfully identified 13 additional communities, bringing the total to 36 relevant clusters.
The third improvement ensured higher community consistency. Given that the embeddings were dense and spread out, large clusters naturally accumulated noise. To counter this, we focused on the "core" of each community: by retaining only the subreddits closest to the centroids, we preserved the most representative samples. Ultimately, the final dataset consists of 6,562 subreddits distributed across 36 high-cohesion clusters.
Results (Pass 1)
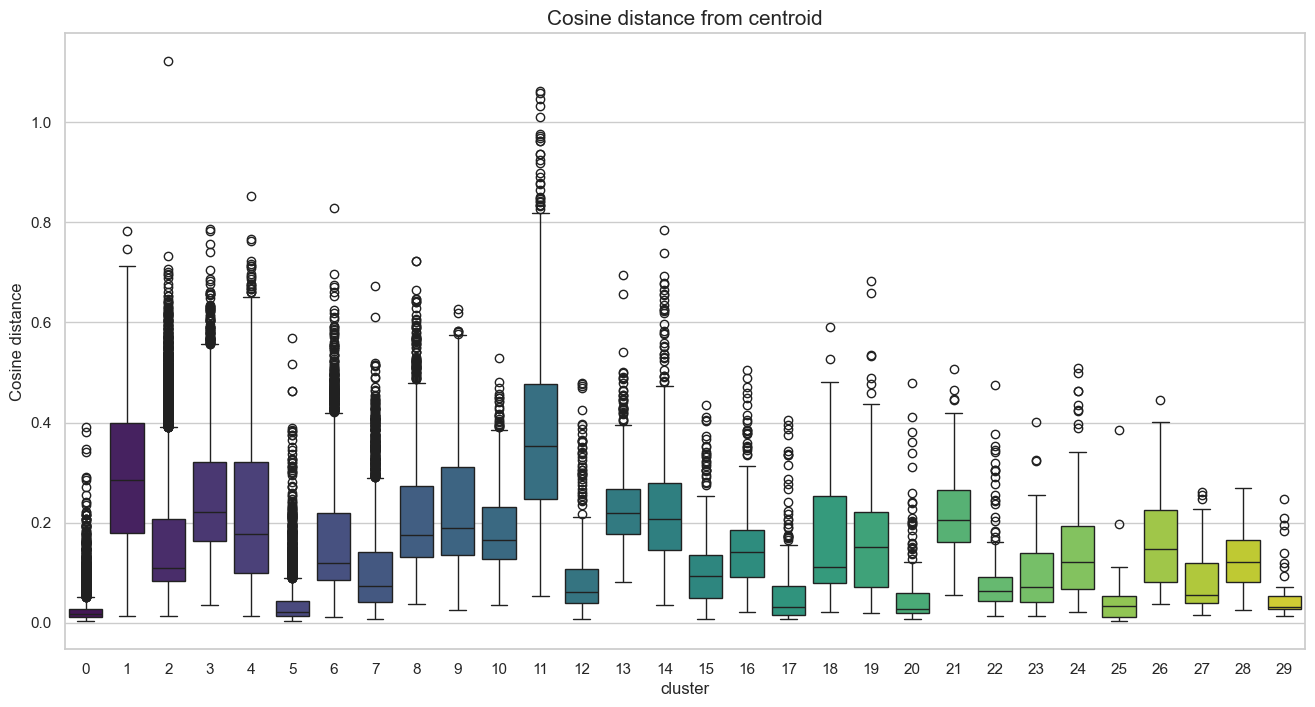
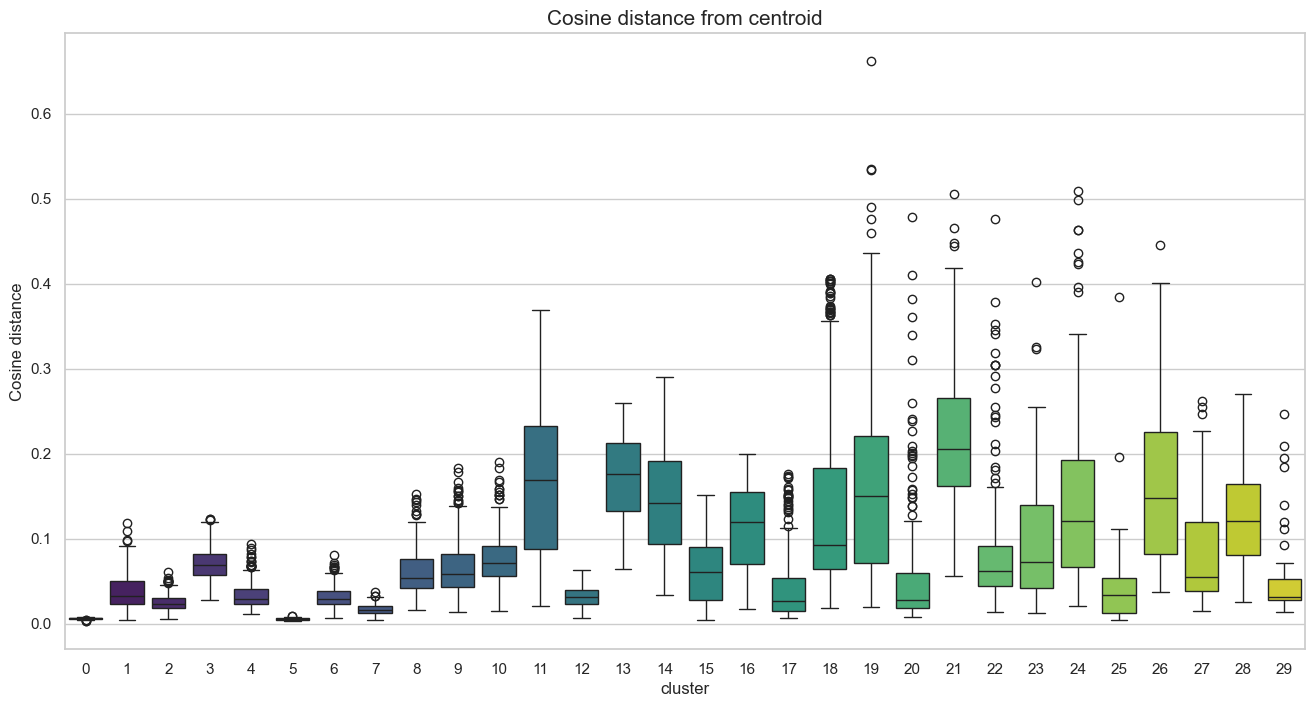
Figure 6 illustrates the distribution following the first clustering pass. Clusters were ranked by size, ranging from 8,070 subreddits in Cluster 0 to 52 in Cluster 29. A significant volume of data points was identified as outliers due to their high distance from the respective centroids.
Figure 7 demonstrates a clear improvement following the distance-based pruning. By retaining only the subreddits closest to each centroid, we achieved a substantial noise reduction, with most distances falling below a 0.5 threshold.
Following this automated refinement, a manual labeling process was conducted. To facilitate this, the ten subreddits closest to each centroid were analyzed for every cluster. This allowed us to validate the thematic consistency of each group and retain only the clusters representing genuine, well-defined communities.
Relevant clusters and assigned label
- 2: Gaming / PC
- 4: Popular / Memes
- 6: Webmarketing / Dev
- 7 - 21 - 22: Adult Content
- 9: Music
- 10: TV / Movies
- 12: Feminine Celebrity
- 13 - 14: Sports (US - Soccer)
- 15: League of Legends
- 16: Crypto / Blockchain
- 17: Fiction / Art
- 18: My Little Pony
- 19: YouTube / Creators
- 23: Japanese Subreddits
- 24: K-Pop
- 25: Metafandom
- 26: Wrestling
- 27: Retrogaming
- 28: Vape
- 29: Educational Video
Examples near centroid
Cluster 2: oxygennotincluded, swgemu, speedrunnersgame, pokemmo, hollowknight, necreopolis, darksoulsmods, sky3ds, gits_fa, playdreadnought
Cluster 9: soothing, noise, music_share, selfmusic, underground_music, experimental, redditoriginals, glitch, remixes, musicinthemaking
Cluster 16: bitcoinuk, counterparty_xcp, trezor, augur, lisk, bitcoin_unlimited, namecoin, primecoin, shadowcash, nubits
Then we took all the subreddits from the remaining clusters and ran clustering again leading to these new clusters:
New clusters found
- 100: R4R / Personals
- 103: Politics / Academics
- 107: Adult Content
- 108: US States and Cities
- 109: Radical Politics
- 111: Adult Content
- 112: India
- 113: Image Of
- 114: Germany
- 115: News Auto
- 116: Radical Politics
- 117: Sweden
- 120: Russia
Final community map
Interesting observations:
First, most of the clusters are dense and well-separated, which successfully achieves our goal of clear topic categorization.
Second, we noticed some interesting outliers within the clusters. When a subreddit seems unrelated but is located at the center of a cluster, it suggests that users from that specific community actively use it, even if the connection isn't obvious at first. However, some points are clearly misplaced: for example, gamingnews was classified in the "My Little Pony" cluster, yet its spatial positioning on the map is between "Retrogaming" and "YouTube/Creators." This visual geography shows where it truly belongs. While a perfect classification is nearly impossible, our objective was to find the best balance between minimizing outliers and retaining as many subreddits as possible.
Third, there is a visible fragmentation within the "Adult Content" category, which is composed of several distinct sub-clusters. This is intentional: to avoid categorizing communities based on specific fetishes, we grouped all pornography-related subreddits under the general "Adult Content" label, even when the algorithm identified distinct sub-communities within that larger group.
Exploring Linguistic Qualities by Community
The data reveals a fascinating spectrum of communication styles. By analyzing the Linguistic Quality Index (LQI) alongside the individual metrics, we can debunk some stereotypes and confirm others.
Use the interactive tool below to compare the "Academic" clusters (highest quality) against the "Casual" clusters (lowest quality), or explore the largest communities on Reddit. For better visual clarity, only clusters with more than 500 posts are included in this comparison.
1. The Crême de la crême
The Hardcore Gamers: Surprisingly, the #1 spot is Hard Videogames. Unlike casual gaming, these communities probably rely on denser theory-crafting and mechanics analysis.
Crypto Complexities: The Crypto cluster (#3) has the highest Cognitive Depth (0.615) in the entire dataset. This suggests that financial and technical discussions drive complex language even more than Politics, this might also show that people in such communities have to communicate in a "correct" and "complex" manner in order to belong to their specific social group.
2. The lower class
Less Formal Communities: Memes/Oddities scores very low (0.393). The data shows low Lexical Richness and Complexity, indicating usual communications are probably built on simpler and less formally organized language. Even though, information density might not be worse than in better scoring communities, the way information is shared is just different.
Artifacts & Other Causes: The Japanese and German Politics clusters score are the lowest probably due to our algorithms struggling with non-English text. Meanwhile, Retrogaming scores surprisingly low compared to modern gaming, likely due to be a more casual community with simpler comments rather than technical analysis.
The Linguistic Galaxy
To visualize the scale of these communities, we mapped the Top 5 and Bottom 5 clusters.
• Size (Slice width): Represents the number of posts (Volume).
• Color (Red to Blue): Represents the Linguistic Quality (LQI).
The diagram below is an Interactive Treemap. It tries to represent as much of the volume of
the dataset
but we had to drop a great quantities of small subreddits for clarity and ease of navigation.
How to use it:
1. Click on a broad topic (e.g., "Gaming") to zoom in.
2. Click on a specific category (e.g., "Esports & Competitive").
3. You will see the subreddits split into High Quality
(Blue)
and Low Quality (Red) relative to their peers.
Key Takeaways from the Data
Click on the cards below to unfold specific anomalies found in the data.
1. The "Code vs. Prose" Paradox
While Tech & Science is the highest scoring category overall (0.621), the internal divide is massive.
- Academic Rigor: Subreddits like r/badhistory (0.977) and r/askscience (0.915) represent the peak of Reddit's formal linguistic code.
- The Utility Drop: Surprisingly, r/programming (0.396) scores very low. This is most likely a data artifact: our algorithms look for sentence variation and prose. Programming discussions consist of code snippets, error logs, and succinct logic—formats that lack the specific linguistic structures ("formalities") our metrics are supposed to quantify.
2. The "Pseudo-Intellectual" Trap
One of the most fascinating findings is the high placement of fringe communities.
r/targetedenergyweapons (0.803) scores significantly higher than most mainstream news subreddits. This most likely confirms a linguistic theory: Conspiracy theorists mimic academic language.
To sound authoritative, these communities utilize dense vocabulary, complex causality connectors ("consequently," "therefore"), and a detached formal tone. They achieve a high LQI score because the structure of their language is complex, even if the content is factually dubious.
3. The Tribal Split: Fans vs. Analysts
Both Gaming and Sports show a clear linguistic divide based on the function of the community:
- The Analysts: Communities like r/truegaming (0.904) and r/atletico (0.838) are top-tier. They mirror the behavior of the "Hard Videogame" cluster identified in our earlier analysis—focusing on theory-crafting and tactics.
- The Fans: Mega-communities like r/pcmasterrace (0.351) and r/lakers (0.423) rank at the bottom. These are "Hype" communities where communication is mostly phatic—cheering, memes, and short reactions—prioritizing speed and emotion over structure.
4. The Surrealist Outlier
The single highest scoring subreddit in the Entertainment category is... r/wackytictacs (0.954).
At first glance, this seems like a bug. It is a meme subreddit. However, it specializes in "Copypastas"—dense blocks of surreal, ironic text.
This highlights a crucial limitation of NLP: distinguishing between authentic intelligence and algorithmic complexity.
5. Linguistic variation across Reddit
The Hierarchy of Intent
By aggregating subreddits into their parent topics (based on the hierarchical tree presented above), we observed a "staircase" of linguistic quality. This confirms that communities self-regulate their speech patterns to fit the social norms of their genre.
Average Linguistic Quality (LQI) by Macro-Genre
Case Study: The Video Game Spectrum
The danger of clustering is over-generalization. If we group r/LeagueOfLegends (an esports news hub) and r/TrueGaming (a discussion forum) under the single label Video Games, we average out their distinct traits. However, our hierarchical analysis reveals a massive internal variance within this specific topic.
The "Play" Communities
- Archetype: r/Gaming, r/Overwatch, r/FIFA
- Avg LQI: 0.32 (Low)
- Trait: High volume, low complexity.
These communities function like a sports bar. The language is characterized by phatic expressions ("GG", "Nice play", "RIP"), slang, and heavy reliance on visual context (video clips). The "Low Quality" score here reflects efficiency, not lack of intelligence.
The "Theory" Communities
- Archetype: r/TrueGaming, r/CompetitiveOverwatch
- Avg LQI: 0.71 (High)
- Trait: Low volume, high complexity.
These communities function like a lecture hall. Users discuss game mechanics, balance updates, and industry trends. To participate, one must write full paragraphs, use technical terminology, and structure arguments logically.
The "Two Faces" of Political Discourse
Politics on Reddit exhibits a unique bimodal distribution. While we initially expected highly polarized "Echo Chambers" to exhibit simple, tribal language, the data reveals a sharp divide based on community format rather than ideology.
Type A: The "War Rooms"
- Examples: r/Politics, r/Conservative, r/Libertarian
- LQI Score: High (~0.65)
In these text-heavy communities, polarization increases linguistic complexity. Users arm themselves with citations, formal rhetoric, and dense paragraphs to win the debate. Here, a high LQI acts as a barrier to entry: if you can't write like a pundit, you get downvoted.
Type B: The "Meme Warriors"
- Examples: r/PoliticalHumor, r/The_Donald, r/LateStageCapitalism
- LQI Score: Low (~0.35)
These communities prioritize viral impact over debate. The discourse is driven by image macros, slogans, and irony. While just as political as Type A, their linguistic fingerprint is identical to r/Funny or r/Gaming.
Political bias itself does not make you dumber (linguistically). The drop in quality only happens when a community shifts from discussing the news to meming it.
Language as a Social Fingerprint
Our analysis demonstrates that Reddit is not a monolith. It is a federation of thousands of micro-nations, each with its own linguistic constitution.
The clustering reveals that Linguistic Quality is functional. High LQI is not inherently better—it is simply the tool used for Storage (History, Science), while Low LQI is the tool used for Flow (Humor, Gaming, Sports). Understanding these traits allows us to map the Digital Geography of the internet, proving that where we post determines how we speak.
6. Linguistic quality and negativity
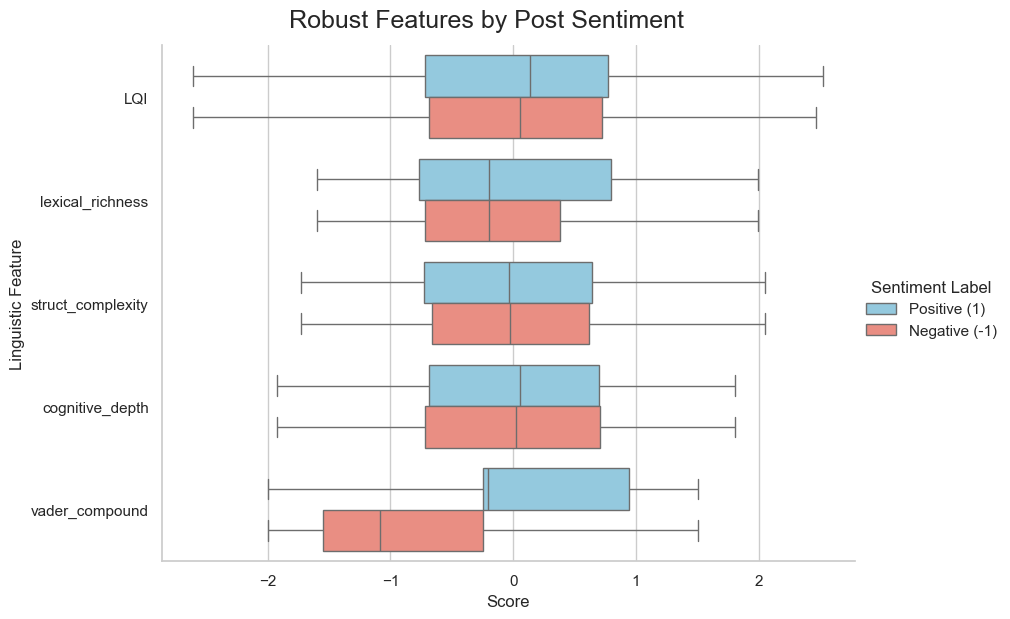
The plot above shows the posts scores for each variable, depending on the posts sentiment link. However, only vader_compound, another measure of sentiment, shows a meaningful difference between positive and negative posts. As such, we cannot dismiss negativity as simply being "low-quality", but indeed both dimensions are capable of both low-quality "slop" and high-quality arguments.
The Trend Line is Misleading
While the red trend line suggests a mild correlation where better writing (higher LQI) aligns with less negativity (R2 = 0.02), the data points form a scattered cloud rather than a clear pattern, indicating that structure is a poor predictor of sentiment. This is largely because the lowest quality writing is often not hostile, but simply brief and happy. Casual comments like "lol" or "This is awesome!" score poorly on complexity metrics but sit at the very bottom of the negativity scale, effectively breaking the assumption that low quality equals low civility.
Complexity Enables Sophisticated Conflict
Conversely, high linguistic competence does not guarantee kindness; it often just provides better tools for aggression. The data reveals distinct clusters of high-LQI posts that are deeply negative, supporting the argument that anger often manifests as detailed, itemized argumentation. Sophisticated writers are just as capable of producing toxic drama as they are polite essays. Therefore, we cannot assume a direct relation because high literacy scales up the capacity for both detailed kindness and complex cruelty.
7. Conclusion
So, who wins the "War of the Learned"? Our analysis shows that Reddit is not a monolith of poor grammar, nor is it a citadel of high intellect. It is a federation of digital city-states, each with its own dialect.
While academic and political communities maintain rigorous standards of Formal Code, other communities have optimized their language for speed and connection (Contextual Code). Defining one as "better" ignores the function of language. However, if you are looking for complex sentence structures and varied vocabulary, you are more likely to find it in a heated political debate than in a friendly fan appreciation thread.